Si vous avez reçu l'avertissement ‘Indexé, bien que bloqué par robots.txt’ dans Google Search Console, vous voudrez le corriger dès que possible, car cela pourrait affecter la capacité de vos pages à se classer dans les pages de résultats des moteurs de recherche (SERPS).
Un fichier robots.txt est un fichier qui se trouve dans le répertoire de votre site web, qui offre des instructions aux robots d'indexation des moteurs de recherche, comme le bot de Google, sur quels fichiers ils doivent et ne doivent pas consulter.
« Indexé, bien que bloqué par robots.txt » indique que Google a trouvé votre page, mais a également trouvé une instruction pour l'ignorer dans votre fichier robots (ce qui signifie qu'elle n'apparaîtra pas dans les résultats).
Parfois cela est intentionnel, ou parfois c'est accidentel, pour un certain nombre de raisons énumérées ci-dessous, et cela peut être corrigé.
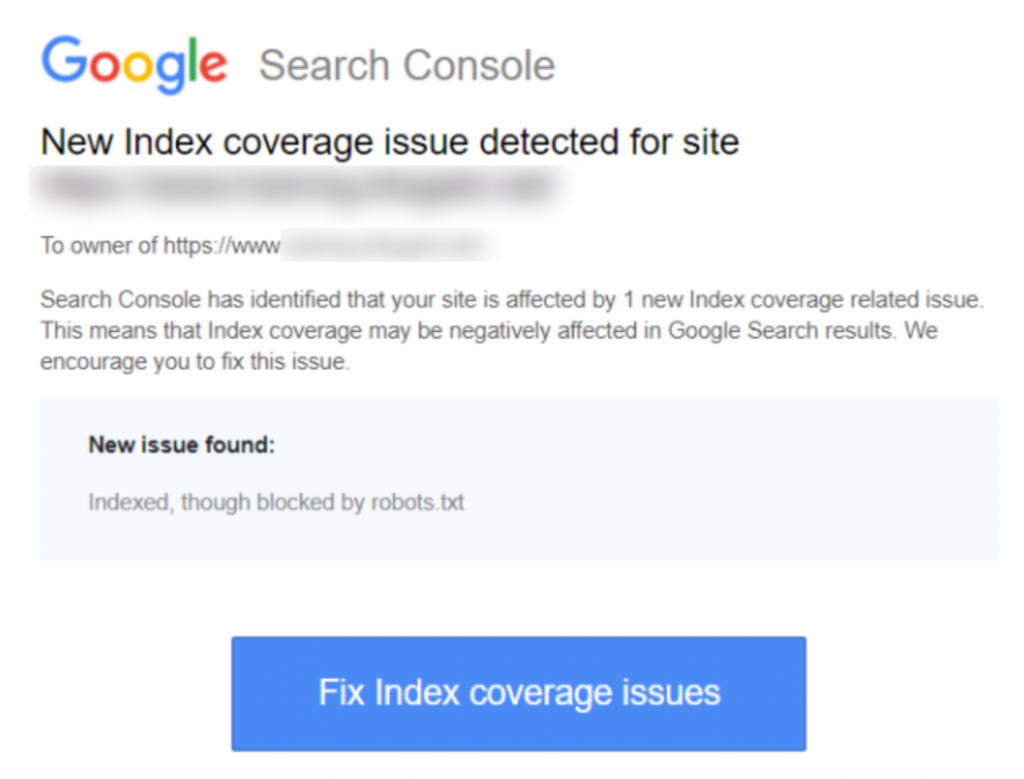
Voici une capture d'écran de la notification :
Identifiez la ou les pages affectées ou les URL(s)
Si vous avez reçu une notification de Google Search Console (GSC), vous devez identifier la ou les page(s) ou URL(s) concernée(s).
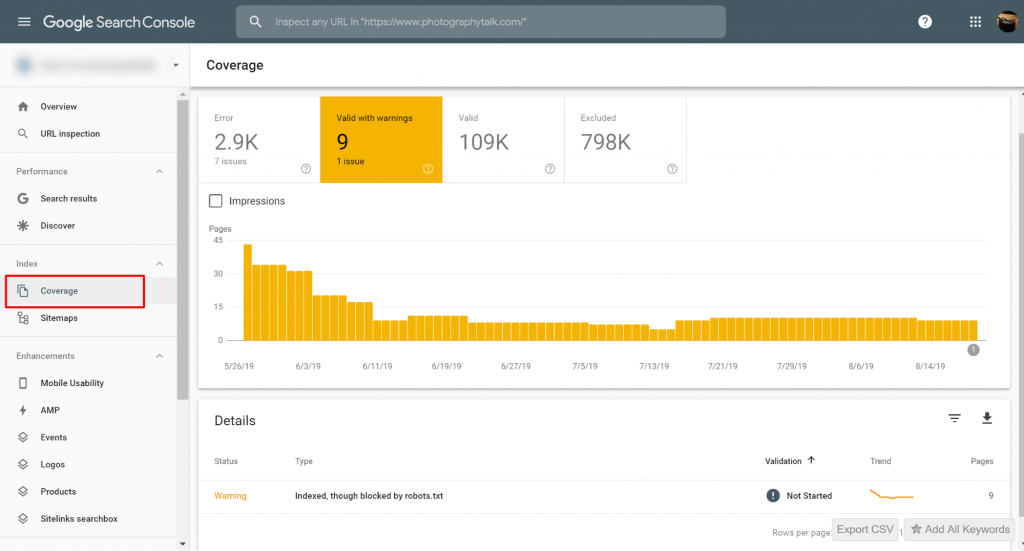
Vous pouvez consulter les pages avec les problèmes Indexé, mais bloqué par le fichier robots.txt sur Google Search Console>>Couverture. Si vous ne voyez pas l'étiquette d'avertissement, alors vous êtes libre et sans problème.
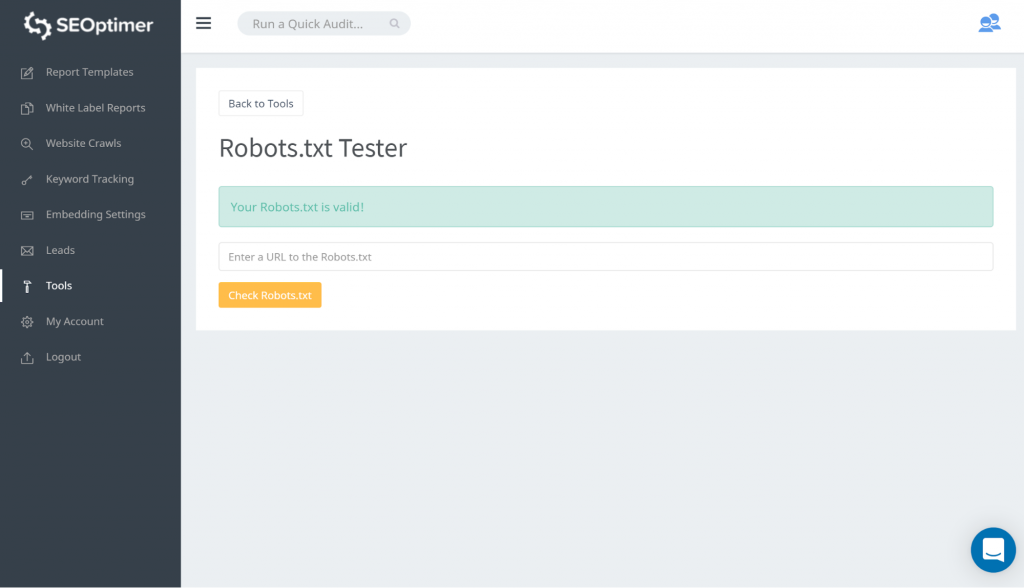
Une manière de tester votre robots.txt est d'utiliser notre testeur de robots.txt. Vous pourriez trouver que vous êtes d'accord avec ce qui est bloqué et que cela reste « bloqué ». Vous n'avez donc pas besoin de prendre de mesures.
Vous pouvez également suivre ce lien GSC. Vous devez ensuite :
- Ouvrez la liste des ressources bloquées et choisissez le domaine.
- Cliquez sur chaque ressource. Vous devriez voir cette fenêtre popup :
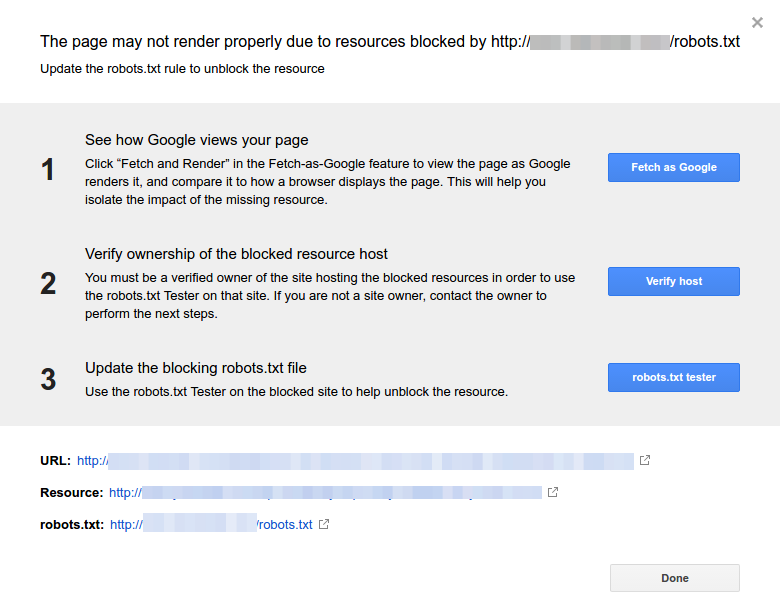
Identifier la raison de la notification
La notification peut résulter de plusieurs raisons. Voici les plus courantes :
Mais d'abord, ce n'est pas nécessairement un problème s'il y a des pages bloquées par robots.txt., Cela peut avoir été conçu pour des raisons telles que, le développeur souhaitant bloquer des pages de catégorie inutiles ou des doublons. Alors, quelles sont les divergences ?
Format d'URL incorrect
Parfois, le problème peut provenir d'une URL qui n'est pas vraiment une page. Par exemple, si l'URL est https://growth.toolzbuy.com/udemy_cloud/fr/?s=digital+marketing, vous devez savoir à quelle page l'URL se résout.
Si c'est une page contenant du contenu significatif que vous voulez vraiment que vos utilisateurs voient, alors vous devez changer l'URL. C'est possible sur des systèmes de gestion de contenu (CMS) comme Wordpress où vous pouvez modifier le slug d'une page.
Si la page n'est pas importante, ou avec notre exemple /?s=digital+marketing, il s'agit d'une requête de recherche de notre blog alors il n'est pas nécessaire de corriger l'erreur GSC.
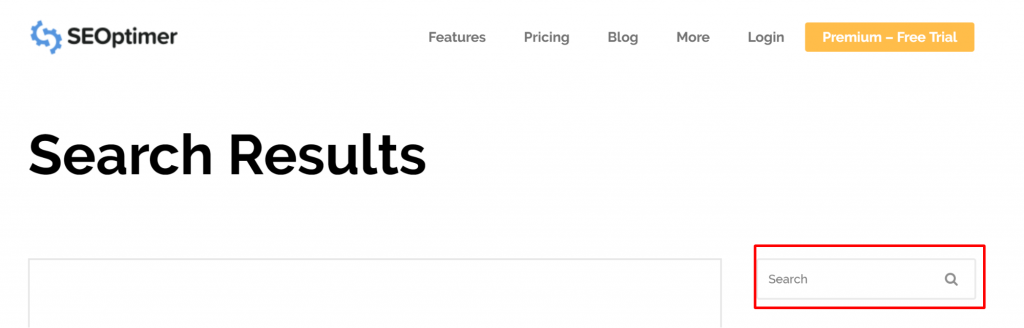
Ça ne fait aucune différence qu'il soit indexé ou non, puisque ce n'est même pas une véritable URL, mais une requête de recherche. Alternativement, vous pouvez supprimer la page.
Pages qui devraient être indexées
Il y a plusieurs raisons pour lesquelles des pages qui devraient être indexées ne le sont pas. En voici quelques-unes :
- Avez-vous vérifié vos directives robots ? Vous avez peut-être inclus des directives dans votre fichier robots.txt qui interdisent l'indexation de pages qui devraient en fait être indexées, par exemple, les tags et les catégories. Les tags et les catégories sont de véritables URL sur votre site.
- Dirigez-vous le Googlebot vers une chaîne de redirections ? Le Googlebot parcourt tous les liens qu'il peut trouver et fait de son mieux pour les lire en vue de l'indexation. Cependant, si vous configurez de multiples redirections longues et profondes, ou si la page est tout simplement inaccessible, le Googlebot pourrait arrêter de chercher.
- Avez-vous correctement implémenté le lien canonique ? Une balise canonique est utilisée dans l'en-tête HTML pour indiquer à Googlebot quelle est la page préférée et canonique en cas de contenu dupliqué. Chaque page devrait avoir une balise canonique. Par exemple, vous avez une page qui est traduite en espagnol. Vous allez auto-canoniser l'URL espagnole et vous voudriez canoniser la page vers votre version anglaise par défaut.
Comment vérifier que votre Robots.txt est correct sur WordPress ?
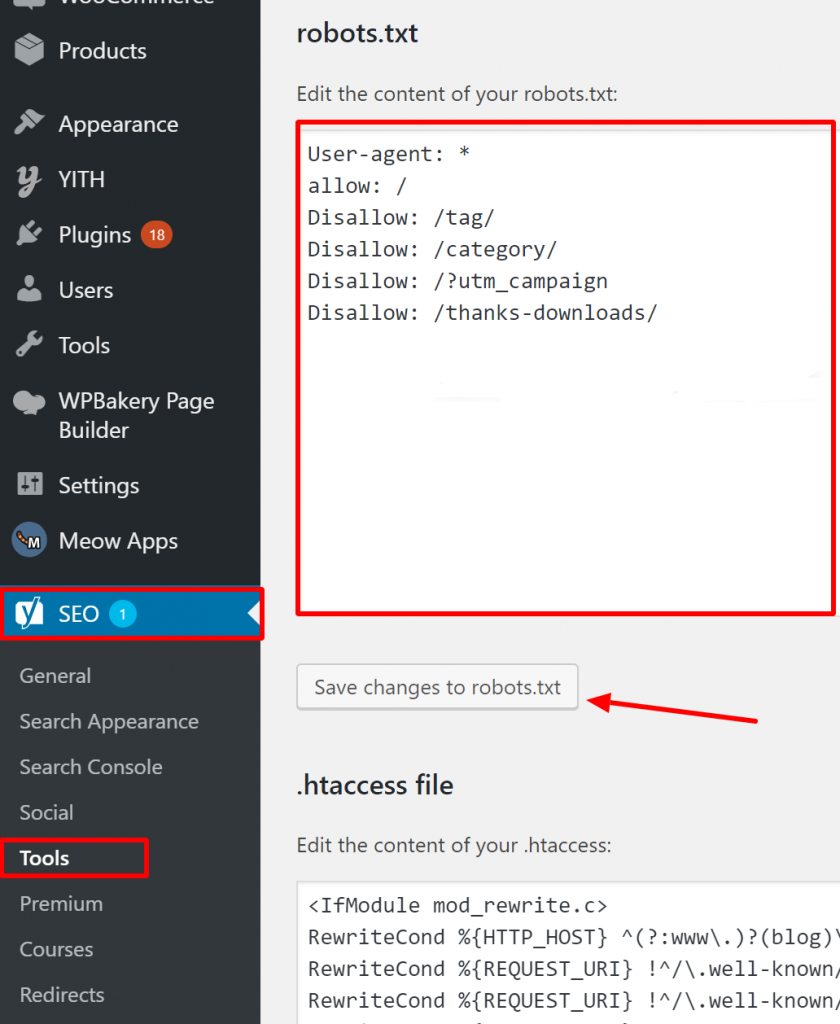
Pour WordPress, si votre fichier robots.txt fait partie de l'installation du site, utilisez le plugin Yoast pour le modifier. Si le fichier robots.txt qui pose problème se trouve sur un autre site qui n'est pas le vôtre, vous devez communiquer avec les propriétaires du site et leur demander de modifier leur fichier robots.txt.
Pages qui ne devraient pas être indexées
Il existe plusieurs raisons pour lesquelles des pages qui ne devraient pas être indexées le sont. En voici quelques-unes :
Directives Robots.txt qui « disent » qu'une page ne doit pas être indexée. Notez que vous devez autoriser la page avec une directive « noindex » à être explorée afin que les robots des moteurs de recherche « sachent » qu'elle ne doit pas être indexée.
Dans votre fichier robots.txt, assurez-vous que :
- La ligne ‘disallow’ ne suit pas immédiatement la ligne ‘user-agent’.
- Il n'y a pas plus d'un bloc ‘user-agent’.
- Caractères Unicode invisibles - vous devez passer votre fichier robots.txt dans un éditeur de texte qui convertira les encodages. Cela supprimera tous les caractères spéciaux.
Les pages sont liées depuis d'autres sites. Les pages peuvent être indexées si elles sont liées depuis d'autres sites, même si elles sont interdites dans le fichier robots.txt. Dans ce cas, cependant, seuls l'URL et le texte d'ancrage apparaissent dans les résultats des moteurs de recherche. Voici comment ces URL sont affichées sur la page de résultats du moteur de recherche (SERP) :
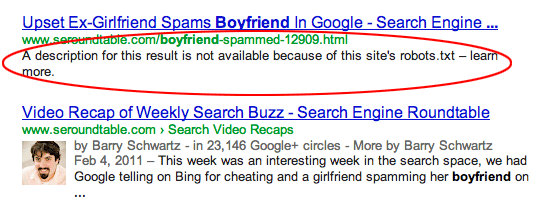 source de l'image Webmasters StackExchange
source de l'image Webmasters StackExchange
Une manière de résoudre le problème de blocage par le fichier robots.txt est de protéger par mot de passe le(s) fichier(s) sur votre serveur.
Alternativement, supprimez les pages du fichier robots.txt ou utilisez la balise meta suivante pour bloquer
eux :
<meta name="robots" content="noindex">
Anciennes URLs
Si vous avez créé un nouveau contenu ou un nouveau site et utilisé une directive ‘noindex’ dans robots.txt pour vous assurer qu'il ne soit pas indexé, ou que vous vous êtes récemment inscrit à GSC, il existe deux options pour résoudre le problème bloqué par robots.txt :
- Donnez à Google le temps d'éliminer éventuellement les anciennes URL de son index
- Redirigez les anciennes URL vers les actuelles avec une redirection 301
Dans le premier cas, Google finit par supprimer les URL de son index si elles ne font que retourner des erreurs 404 (ce qui signifie que les pages n'existent pas). Il n'est pas conseillé d'utiliser des plugins pour rediriger vos erreurs 404. Les plugins pourraient causer des problèmes qui pourraient conduire à ce que GSC vous envoie l'avertissement « bloqué par robots.txt ».
Fichiers robots.txt virtuels
Il existe une possibilité de recevoir des notifications même si vous n'avez pas de fichier robots.txt. Cela est dû au fait que les sites basés sur des CMS (Systèmes de Gestion de Contenu), par exemple WordPress, disposent de fichiers robots.txt virtuels. Les plug-ins peuvent également contenir des fichiers robots.txt. Ceux-ci pourraient être à l'origine des problèmes sur votre site.
Ces fichiers robots.txt virtuels doivent être remplacés par votre propre fichier robots.txt. Assurez-vous que votre robots.txt inclut une directive pour permettre à tous les robots des moteurs de recherche de parcourir votre site. C'est la seule manière pour eux de déterminer les URL à indexer ou non.
Voici la directive qui permet à tous les robots d'explorer votre site :
User-agent: *
Interdire : /
Cela signifie « ne rien interdire ».
En conclusion
Nous avons examiné l'avertissement « Indexé, bien que bloqué par robots.txt », ce que cela signifie, comment identifier les pages ou URL affectées, ainsi que la raison derrière l'avertissement. Nous avons également vu comment le résoudre. Notez que l'avertissement n'équivaut pas à une erreur sur votre site. Cependant, ne pas le corriger pourrait entraîner le non-indexation de vos pages les plus importantes, ce qui n'est pas bon pour l'expérience utilisateur.